Lesson 01 - Introduction to Machine Learning¶
The following topics are discussed in this notebook:¶
- Overview of machine learning.
- Discussion supervised vs unsupervised learning.
- Examples of regression and classification tasks.
- Examples of clustering tasks.
Additional Resources¶
- Hands-On Machine Learning, Chapter 01
- Python Data Science Handbook, Chapter 05, What is Machine Learning?

What is Machine Learning¶
Machine learning is a subfield of artificial intelligence in which computers are trained to perform certain tasks through observation and iteration, rather than by following a set of rules that have been explicitly programmed by a human. In a sense, a machine learning algorithm allows the computer to "learn" how to complete a task through trial and error. In many cases, this approach is simpler to implement than developing explicit rules, and is often more effective.
Applications of Machine Learning¶
Machine learning has applications in many fields. A (non-exaustive) list of applications includes spam detection, generating search results, image classification, voice recognition, programming autonomous vehicles, predicting credit scores, predicting housing costs, medical diagnoses, recommender systems, and handwriting recognition.
Types of Machine Learning Algorithms¶
There are three main categories of machine learning problems: supervised learning, unsupervised learning, and reinforcement learning.
In this class, we will focus primarily on supervised learning, but will also see a bit of unsupervised learning.
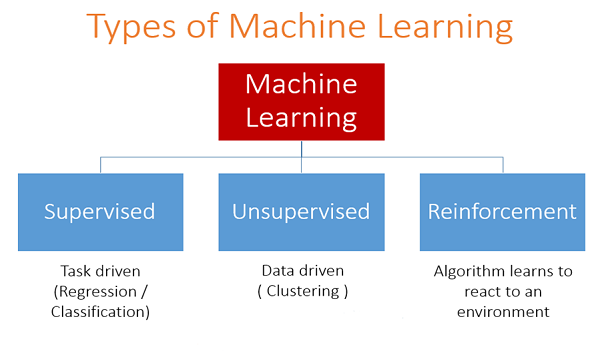
Supervised Learning¶
In a supervised learning task, the goal is to generate a model or prediction function that can predict an output based on one or more input values.
- The output of the model is typically called a label, target value, or response variable.
- The inputs into the model are typically called features or predictors.
The algorithm "learns" the optimal model by studying a training set of data that consists of several observations (or instances, or samples), each of which contains values for both its features and its label. You can imagine a supervised learning algorithm as a function that takes training data as input, and that produces a model, or prediction function, as its output.
Regression and Classification¶
Supervised learning tasks can be further grouped into regression and classification problems, based on whether the labels are continuous and real-valued or categorical.
- Regression. A regression task is one for which the target values are continuous, real numbers. Examples of regression tasks include:
- Predicting a credit score.
- Predicting the sale price of a home.
- Predicting blood pressure.
- Predicting dimensions of an organism.
- Classification. A classification task is one for which the target values are discrete classes. Examples of classification tasks include:
- Predicting whether a loan is "high risk" or "low risk".
- Predicting the species of an organism based on measurements.
- Classifying elements within an image.
- Recognizing images of hand-written letters or digits.
- Voice recognition.
Example of a Regression Task¶
The cell below shows a small data set that could be used for a regression task. The horizontal axis represents the single feature, while the vertical axis represents the continuous label.
The cell also displays plots of 5 prediction functions (or modles) that were generated using different regression algorithms.
%matplotlib inline
%run -i snippets/snippet01.py

Example of a Classification Task¶
The cell below shows the plot of a sythetic data set created for use in a classification task. The two axes represent two different features. Each point represents a singple observation. Each observation is assigned on of two classes, "Orange" or "Blue", as indicated by the color of the point.
The prediction function generated by a classification algorithm would assign one of the two classes to each point in the plane. The cell below shows the regions designated as being in each class according to 5 different classification algorithms.
%run -i snippets/snippet02.py

Unsupervised Learning¶
In unsupervised learning, we work with data sets in which features are provided, but no labels. Not only are the labels "missing", but we typically do not start an unsupervised learning tasks with a preconception of what the possible labels might be. The goal of unsupervised learning is to identify structure within the data that might not be readily perceptible to humans.
Some common unsupervised learning tasks are:
- Clustering
- Outlier Detection
- Feature extraction
The cell below shows the results of applying a clustering algorithm to an unlabeled dataset. The algorithm used in this example is referred to as K-means clustering.
%run -i snippets/snippet03.py

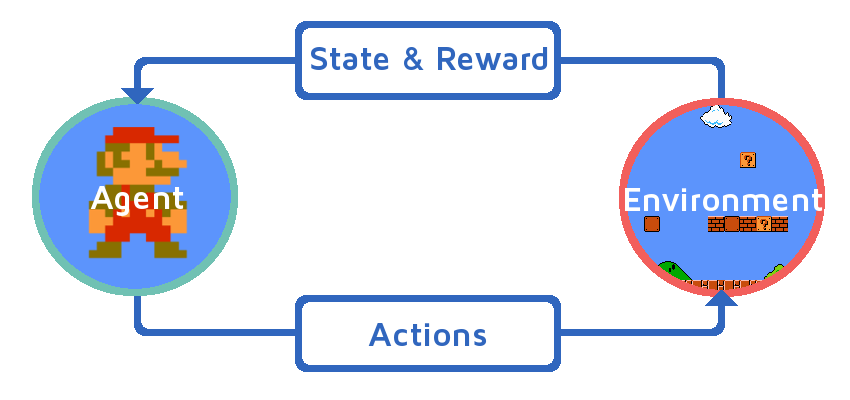
Reinforcement Learning¶
Reinforcement learning is a branch of machine learning concerned with training an AI to interact with an virtual environment to perform a specific task. Examples of reinforcement learning tasks include training an algortihm to play chess, to play a video game, or to navigate a self-driving car.
In reinforcement learning, a software agent is provided with rules governing how it can interact with its environment. A goal is set for the agent, and a method is provided to score how successful the agent is at accomplishing that task. The RL algorithm then collects a training set through trial-and-error. Which each new attempt, the agent receives feedback regarding its performance, and then makes adjustments as needed.
Some links to YouTube videos demonstrating interesting applications of reinforcement learning are provided below.