Random Number Generation¶
In this lesson, we will learn how to ask Python to generate random numbers. Although base Python has the ability to generate random numbers, this functionality is extended in NumPy.
import numpy as np
import matplotlib.pyplot as plt
Random Sampling¶
The numpy.random.choice() function in NumPy can be use to randomly generate samples. The parameters for this function are as follows:
a: An array, list, or range that the sample will be drawn from.
size: The number of elements to be drawn for the sample. This can be an integer, in which case the function will return a list containing that many observations sampled from the population provided, or
None, in which case the function will return a single value (not in a list). The default value isNone.replace: A boolean value that determines if elements are returned to the sample after being drawn. The default value is
True.p: An array or list that determines the probability of drawing each of the elements. If p is not specified, then all elements will be equally likely.
Let’s start with a simple example.
#die_roll = np.random.choice(range(1,7))
die_roll = np.random.choice(range(1,7), size=None)
print(die_roll)
2
We can draw samples of any size.
eight_rolls = np.random.choice(range(1,7), size=8)
print(eight_rolls)
[4 1 2 6 2 5 1 1]
If we set size=1, we will get an array contining a single observation. If, on the other hand, we leave size with its default value of None, then np.random.choice() will return an integer.
one_roll = np.random.choice(range(1,7), size=1)
print(one_roll)
#print(type(one_roll))
[1]
By default, each value in a is equally likely to be drawn for any given observation. We can use the p parameter to specify the probability of individual values being drawn.
loaded_die = np.random.choice(range(1,7), size=10, p=[0.5, 0.2, 0.1, 0.1, 0.05, 0.05])
print(loaded_die)
[1 1 1 2 6 1 1 1 3 2]
We can also generate observations drawn from non-numerical lists.
my_sample = np.random.choice(['A', 'B', 'C'], size=10)
print(my_sample)
['C' 'C' 'B' 'C' 'A' 'A' 'C' 'A' 'C' 'C']
If we set replace=False, then each value in a will only be able to selected at most once for the sample.
names = ['Anna', 'Beth', 'Chad', 'Drew', 'Emma', 'Fred', 'Gary', 'Hana', 'Iris', 'Jake']
group = np.random.choice(names, size=5, replace=False)
print(group)
['Emma' 'Fred' 'Hana' 'Anna' 'Chad']
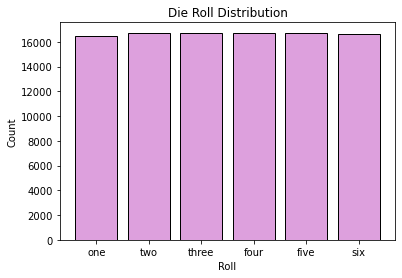
Example: Simulating the Distribution of Die Rolls¶
In this example, we will simulate a die roll being rolled many times. We will count the number of times each value was rolled, and will generate a bar chart to graphically summarize the results.
many_rolls = np.random.choice(range(1,7), 100000)
n1 = np.sum(many_rolls == 1)
n2 = np.sum(many_rolls == 2)
n3 = np.sum(many_rolls == 3)
n4 = np.sum(many_rolls == 4)
n5 = np.sum(many_rolls == 5)
n6 = np.sum(many_rolls == 6)
roll_dist = [n1, n2, n3, n4, n5, n6]
labels = ['one', 'two', 'three', 'four','five', 'six']
plt.bar(labels, roll_dist, edgecolor='black', color='plum')
plt.xlabel('Roll')
plt.ylabel('Count')
plt.title('Die Roll Distribution')
plt.show()
Using Simulation to Estimate Probabilities¶
Assume that we are interested in calculating the probability of a certain outcome of a statistical experiment, but that this particular probability is difficult, or perhaps even impossible, to calculate directly. We can sometimes estimate such probabilities using simulation. To use this approach, we would first write code that simulates the outcome of the experiment, and then run the experiment a very large number of times and count the number of simulated experiments that resulted in the outcome of interest. The proportion of experiments resulting in this outcome is an estimate of the probability of the outcome occurring.
Example: Coin Flipping¶
Assume that we are interested in know the probability of getting a certain number of “Heads” in 50 coin flips. This is a very common problem to encounter in an introductory Statistics course, and is solvable using basic probability techniques. However, we will estimate the answer using simulation.
We will first write a function that simulates a sequence of 50 coin flips.
def flip_50():
return np.random.choice(['H','T'], 50)
print(flip_50())
['T' 'H' 'H' 'H' 'T' 'H' 'T' 'H' 'T' 'H' 'T' 'H' 'T' 'T' 'T' 'H' 'T' 'T'
'T' 'H' 'T' 'H' 'H' 'H' 'H' 'H' 'H' 'H' 'H' 'H' 'T' 'H' 'T' 'H' 'H' 'T'
'T' 'H' 'H' 'H' 'H' 'T' 'H' 'H' 'T' 'T' 'T' 'H' 'T' 'T']
Now, we will run this simulation 100,000 times. After each simulation, we will count the number of heads in the sequence, and will record this number in a list. Finally, we will convert this list to an array.
num_heads = []
for i in range(0,100000):
seq = flip_50()
count = np.sum(seq == 'H')
num_heads.append(count)
num_heads = np.array(num_heads)
print(num_heads[:20])
[22 31 23 27 23 26 23 26 26 32 23 28 18 30 23 25 25 28 27 26]
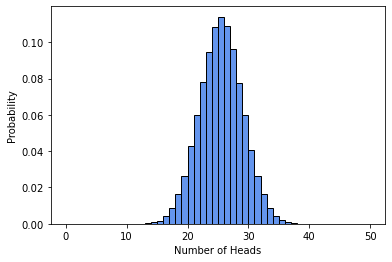
Suppose we want to estimate the probability of getting 20 or fewer heads in 50 flips. The code below provides such an estimate. The true value of this probability is approximately 0.101319.
prob_20_or_fewer = np.mean(num_heads <= 20)
print(prob_20_or_fewer)
0.10226
We can graphically represent the probabilities of getting any specific number of heads with a histogram.
plt.hist(num_heads, bins=range(0,51), density=True, edgecolor='black', color='cornflowerblue')
plt.xlabel('Number of Heads')
plt.ylabel('Probability')
plt.show()
Example: Random Walks¶
A random walk is a path that consists of several consecutive steps taken in a random direction. The size of the steps could be random, or it could be preset. Random walks have many applications in fields such as computer science, physics, biology, chemistry, and economics.
We will consider perhaps the most basic example of a random walk. In this example, the position is recorded as a single integer, and the starting position is 0. At each step, we either move by an amount of either +1 or -1, with equal probability.
def random_walk(start = 0, n = 1000):
steps = np.random.choice([-1,1], n)
path = start + np.cumsum(steps)
path = np.concatenate(([start], path))
return path
Let’s print the path of random walk starting at 10 and having 20 steps.
print(random_walk(10, 20))
[10 11 10 9 8 9 10 9 8 9 10 9 10 11 10 9 8 9 10 11 10]
The code below will plot a random walk starting at 50 and consisting of 100 steps. Run it several times.
plt.plot(random_walk(50, 1000))
plt.show()
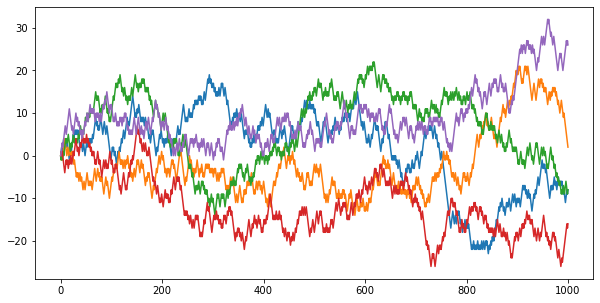
In the following cell, we will plot five random walks starting at 0 and with 1000 steps.
fig=plt.figure(figsize=(10, 5))
plt.plot(random_walk())
plt.plot(random_walk())
plt.plot(random_walk())
plt.plot(random_walk())
plt.plot(random_walk())
plt.show()
Example: Stock Price Simulation¶
In the next example, we will create a function that generates simulated prices for a stock over a period of several days. Before jumping into the code, we will discuss some terminology, as well as the formulas that we will be using.
A yield rate for a stock is (roughly speaking) the percentage increase or decrease in the value of the stock over a certain period. Suppose that the price of a stock today is 100 and the stock has a yield rate of 12% over the next year. Then the price of the stock at the end of the year will be \(100⋅e^{0.12}=112.75\).
Let \(S_0\) denote the current price of a stock. Suppose that we randomly generate simulated daily yield rates for the stock over the next n days. Denote these simulated rates as \(R_1,R_2,…,R_n\). Let \(S_t\) denote the price of the stock at the end of day \(t\). Then simulate value of \(S_t\) is given by \(S_t=S_0 \cdot e^R_1\cdot e^R_2 \cdot ... \cdot e^R_t\), or \(S_t = S_0 \cdot e^{R_1 + R_2 + ... + R_t}\). For convenience, define the cumulative yield rate on day \(t\) to be \(CR_t = R_1 + R_2 + ... + R_t\). Then we can write the formula for the simulated price on day \(t\) as \(S_t=S_0 \cdot e^{CR_t}\).
Let’s explain these concepts with an example:
Assume that the current price of the stock is 120.
Suppose that the simulated daily yields over the next 5 days (\(R_1\) through \(R_5\)) are given by: \(\left[0.02, 0.01, -0.04, 0.03, 0.05\right]\)
Then the cumulative daily yields (\(CR_1\) through \(CR_5\)) are given by: \(\left[0.02, 0.03, -0.01, 0.02, 0.07 \right]\)
The simulated daily prices would be given by: \(\left[120 \cdot e^{0.02}, 120\cdot e^{0.03}, 120\cdot e^{-0.01}, 120 \cdot e ^{0.02}, 120 \cdot e^{0.07} \right]\)
We will now create a function that simulates a sequence of several daily prices for a stock. We will assume (somewhat simplistically) that the stock price will see a percentage change equal to one of the following amounts each day:
-0.5%, -0.4%, -0.3%, -0.2%, -0.1%, 0%, 0.1%, 0.2%, 0.3%, 0.4%, 0.5%
We will also assume that each of these changes is equally likely.
def sim_stock(start=100, n=100):
rate_choices = [-0.005, -0.004, -0.003, -0.002, -0.001, 0, 0.001, 0.002, 0.003, 0.004, 0.005]
daily_yields = np.random.choice(rate_choices, n)
cumulative_yields = np.cumsum(daily_yields)
daily_multipliers = np.exp(cumulative_yields)
daily_prices = start * daily_multipliers
daily_prices = np.concatenate(([start], daily_prices))
return np.round(daily_prices,2)
Let’s generate a sequence of 10 simulated daily prices for a stock currently work 50.
print(sim_stock(start=50, n=10))
[50. 50.2 50.45 50.6 50.5 50.45 50.6 50.55 50.5 50.25 50.35]
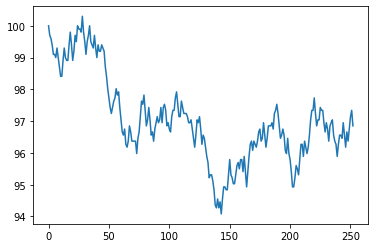
In the cell below we plot the simulated daily prices of a stock currently worth 100 over the course of a year. There are 252 trading days in a year, so we will use 252 for the parameter n.
plt.plot(sim_stock(100, 252))
plt.show()
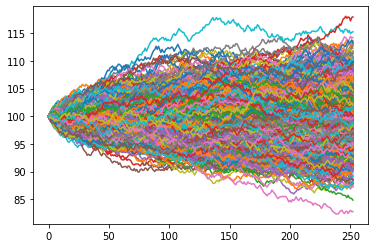
To get a sense of the range of possible outcomes for our stock model after one year, let’s plot 1000 simulated sequences, or runs, of daily stock prices.
for i in range(1000):
plt.plot(sim_stock(100, 252))
plt.show()
Assuming that our stock model correctly describes the range of possibilities for our stock, we can run several simulations and then use the results to estimate probabilities relating to the price of the stock.
In the cell below, we create 10,000 simulations for the price of the stock over the course of a year. We then use these simulations to estimate the probability that the price of the stock will be greater than 105 a year from now.
final_prices = []
for i in range(100000):
run = sim_stock(100,365)
final_prices.append(run[-1])
final_prices = np.array(final_prices)
print(np.mean(final_prices > 105))
0.21156
We might be interested in estimating a probability such as the one above if we are considering a certain type of investment whose value is based on the price of the stock after one year. For example, a call option is a type of financial instrument that will provide its purchaser with a positive payoff if the value of the stock is greater than a certain pre-determined value at the end of a specified period.
Sampling from Statistical Distributions¶
Numpy also provides us with tools for sampling from various probability distributions. We will discuss how to sample from the uniform, normal, and gamma distributions.
The Uniform Distribution¶
If a random variable follows a uniform distribution on an interval [a,b], then the result of the randomly generated value for the variable can take on any value from the interval [a,b], and is just as likely to come from one portion of the interval as any other.
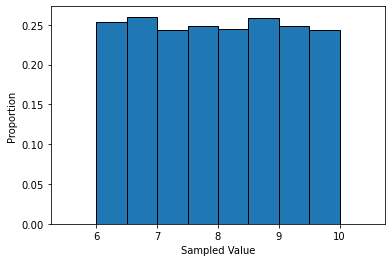
We can use the function np.random.uniform() to sample from a uniform distribution.
unif_sample = np.random.uniform(low=6, high=10, size=10000)
plt.hist(unif_sample, bins=np.arange(5.5,11,0.5), density=True, edgecolor='black')
plt.xlabel('Sampled Value')
plt.ylabel('Proportion')
plt.show()
The Normal Distribution¶
A normal distribution is defined by two numbers: A mean \(\mu\) and a standard deviation \(\sigma\). If a random variable follows a normal distribution, then it can take on any real number as its value, but the observed values will tend to fall close to the mean \(\mu\). The parameter \(\sigma\) determines how likely it is that observations will fall close to the mean. Small values of \(\sigma\) will result in observations that are clustered very near the mean, while large values of \(\sigma\) will result in observations being more spread out.
We can use the function np.random.normal() to sample from a normal distribution.
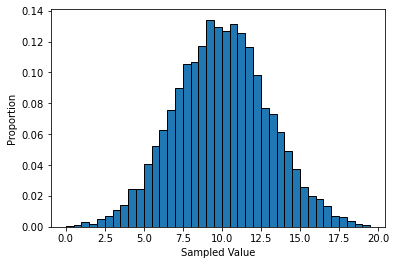
norm_sample = np.random.normal(loc=10, scale=3, size=10000)
plt.hist(norm_sample, bins=np.arange(0,20,0.5), density=True, edgecolor='black')
plt.xlabel('Sampled Value')
plt.ylabel('Proportion')
plt.show()
Let’s use 1,000,000 simulated values to estimate probabilities associated with the normal distribution.
X = np.random.normal(loc=10, scale=2, size=1000000)
print('Prob[X < 10] = ', np.mean(X < 10))
print('Prob[X < 12] = ', np.mean(X < 12))
print('Prob[8 < X < 12] =', np.mean((X > 8) & (X < 12)))
print('Prob[6 < X < 14] =', np.mean((X > 6) & (X < 14)))
print('Prob[4 < X < 16] =', np.mean((X > 4) & (X < 16)))
Prob[X < 10] = 0.499196
Prob[X < 12] = 0.841218
Prob[8 < X < 12] = 0.682724
Prob[6 < X < 14] = 0.954818
Prob[4 < X < 16] = 0.997292
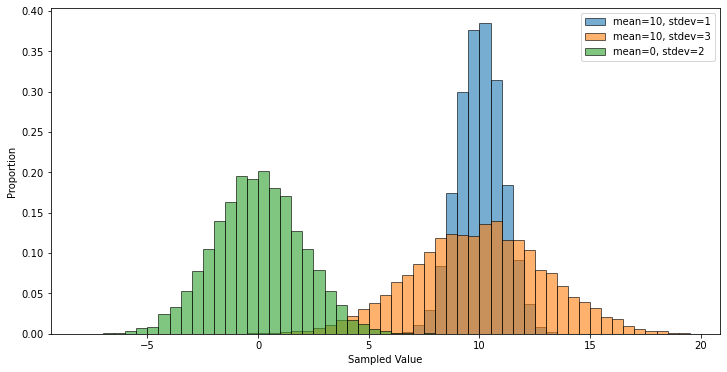
In the cell below, we sample 10,000 observations each from three different normal distrubutions, and then plot the results. This illustrates the effects that the loc (mean) and scale (standard deviation) parameters have on the shape of the distribution.
norm_sample_1 = np.random.normal(loc=10, scale=1, size=10000)
norm_sample_2 = np.random.normal(loc=10, scale=3, size=10000)
norm_sample_3 = np.random.normal(loc=0, scale=2, size=10000)
fig=plt.figure(figsize=(12, 6))
plt.hist(norm_sample_1, bins=np.arange(-8,20,0.5), density=True,
edgecolor='black', alpha=0.6, label="mean=10, stdev=1")
plt.hist(norm_sample_2, bins=np.arange(-8,20,0.5), density=True,
edgecolor='black', alpha=0.6, label="mean=10, stdev=3")
plt.hist(norm_sample_3, bins=np.arange(-8,20,0.5), density=True,
edgecolor='black', alpha=0.6, label="mean=0, stdev=2")
plt.xlabel('Sampled Value')
plt.ylabel('Proportion')
plt.legend()
plt.show()
The Gamma Distribution¶
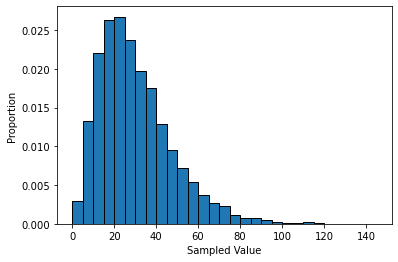
If a random variable follows a Gamma Distribution, then it can take on any positive value, and have a right-skew, meaning that very large values are possible, but rare. Gamma distributions are often used to model the amount of time until an event, such as the failure of a mechanical device, or until an earthquake.
We can use the function np.random.gamma() to sample from a gamma distribution.
gamma_sample = np.random.gamma(shape=3, scale=10, size=10000)
plt.hist(gamma_sample, bins=np.arange(0,150,5), density=True, edgecolor='black')
plt.xlabel('Sampled Value')
plt.ylabel('Proportion')
plt.show()
Pseudorandom Numbers and Seeds¶
The numbers generated by functions in np.random are not truly random. Typical computers are simply not capable of “true” randomness. The numbers generated by functions in np.random are obtained from a pseudorandom number generator.
Pseudorandom number generators create sequences of numbers that satisfy certain statistical properties that we would expect from “truly random” numbers. The sequences are algorithmically generated from a base value, which is called the seed. To ensure that the results are different each time, a pseudorandom number generator will typically use a source such as the computer’s system clock to seed the algorithm. However, we are able to set the seed ourselves manually. This ensures that we get the same “random” results each time we run a code involving pseudorandom numbers. This is useful for occasions when we want to generate results that behave randomly, but are reproducible.
We can set the seed for the numpy pseudorandom number generator using the function np.random.seed().
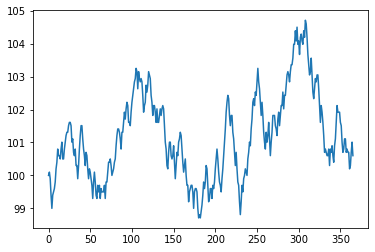
In the cell below, we set a seed of 137 before running the sim_stock() function. We will get the same results every time we run this cell with this seed value. Experiment by changing the value of the seed and running the cell multiple times with the new seed value.
np.random.seed(137)
plt.plot(sim_stock(100, 365))
plt.show()
Pseudorandom Sampling Algorithm¶
In the cell below, we provide an example of a pseudorandom sampling algorithm. The goal of the algorithm is to sample an element at random from a list stored in the parameter x. The algorithm first obtains the current system time in seconds using time.time(), and then multiplies this by a trillion to get the time in picoseconds. It then converts this value to an integer and stores the result in seed. We then obtain the length of the list n, and then calculate the remainder of seed after dividing by n. This will generate an idx that will be between 0 and n-1, inclusive. We then use idx as an index to select and return an element from x.
import time
def my_random(x):
seed = int(time.time() * 1000000000000)
n = len(x)
idx = seed % n
return x[idx]
Notice that the element returned by this function will change every picosecond. Run the cell below several times to confirm that the sampled value is different with each call to the function.
random_value = my_random([1,2,3,4,5])
print(random_value)
5
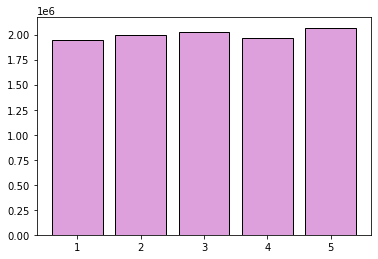
In the cell below, we call the my_random() function ten million times, storing the resulting value in a list. We then count the number of times each of the five possible values was sampled, and display a histogram of the results. You can see that the distribution of sampled values seems fairly uniform.
results = []
for i in range(10000000):
temp = my_random([1,2,3,4,5])
results.append(temp)
results = np.array(results)
counts = [np.sum(results == i) for i in range(1,6)]
plt.bar([1,2,3,4,5], counts, edgecolor='black', color='plum')
plt.show()